Interesting points I found in Pierpaolo Dondio and Stephen Barrett, "Computational Trust in Web Content Quality: A Comparative Evalutation on the Wikipedia Project",
Informatica 31 (2007) 151–160
AbstractThe problem of identifying useful and trustworthy information on the World Wide Web is becoming increasingly acute as new tools such as wikis and blogs simplify and democratize publication. It is not hard to predict that in the future the direct reliance on this material will expand and the problem of evaluating the trustworthiness of this kind of content become crucial. The Wikipedia project represents the most successful and discussed example of such online resources. In this paper we present a method to predict Wikipedia articles trustworthiness based on computational trust techniques and a deep domain-specific analysis. Our assumption is that a deeper understanding of what in general defines high-standard and expertise in domains related to Wikipedia – i.e. content quality in a collaborative environment – mapped onto Wikipedia elements would lead to a complete set of mechanisms to sustain trust in Wikipedia context. We present a series of experiment. The first is a study-case over a specific category of articles; the second is an evaluation over 8 000 articles representing 65% of the overall
Wikipedia editing activity. We report encouraging results on the automated evaluation of Wikipedia content using our domain-specific expertise method. Finally, in order to appraise the value added by using domain-specific expertise, we compare our results with the ones obtained with a pre-processed cluster analysis, where complex expertise is mostly replaced by training and automatic classification of common features.
I thought interesting:
Ciolek, T., Today's WWW, Tomorrow's MMM: The specter of multi-media mediocrity, IEEE
COMPUTER, Vol 29(1) pp. 106-108, January 1996.
Predicted a seriously negative future for online content quality by describing the World
Wide Web (WWW) as
“a nebulous, ever-changing multitude of computer sites that house continually changing chunks of multimedia information, the global sum of the uncoordinated activities of several hundreds of thousands of people”.....On one hand, recent exceptional cases have brought to the attention the question of Wikipedia trustworthiness. In an article published on the 29th of November in USA Today , Seigenthaler, a former administrative assistant to Robert Kennedy, wrote about his anguish after learning about a false Wikipedia entry that listed him as having been briefly suspected of involvement in the assassinations of both John Kennedy and Robert Kennedy. The 78-year-old Seigenthaler got
Wikipedia founder Jimmy Wales to delete the defamatory information in October. Unfortunately, that was four months after the original posting. The news was further proof that Wikipedia has no accountability and no place in the world of serious information gathering .
How much do you trust wikipedia? (March 2006)
http://news.com.com/20091025_3-5984535.htmlIn December 2005, a detailed analysis carried out by the magazine Nature compared the accuracy of Wikipedia against the Encyclopaedia Britannica. Nature identified a set of 42
articles, covering a broad range of scientific disciplines, and sent them to relevant experts for peer review. The results are encouraging: the investigation suggests that Britannica’s advantage may not be great, at least when it comes to science entries. The difference in accuracy was
not particularly great: the average science entry in Wikipedia contained around four inaccuracies; Britannica, about three. Reviewers also found many factual errors, omissions or misleading statements: 162 and 123 in Wikipedia and Britannica respectively.
Gales, J. Encyclopaedias goes head a head, Nature Magazine, issue N. 438, 15, 2005
Trust“trust is a subjective assessment of another’s influence in terms of the extent of one’s perceptions about the quality and significance of another’s impact over one’s outcomes in a given situation, such that one’s expectation of, openness to, and inclination toward such influence provide a sense of control over the potential outcomes of the situation.” - Romano
Computational trust was first defined by S. Marsh, as a new technique able to make agents less vulnerable in their behaviour in a computing world that appears to be malicious rather than cooperative, and thus to allow interaction and cooperation where previously there could be none.
Ziegler and Golbeck studied interesting correlation between similarity and trust among social network users: there is indication that similarity may be evidence of trust.
The most visited and edited articles reach an average editing rate of 50 modifications per day..."Speed" is one of the requirements that conventional techniques do not match up to.
In general, user past-experience with a Web site is only at 14th position among the criteria
used to assess the quality of a Web site with an incidence of 4.6% . We conclude that a mechanism to evaluate articles trustworthiness relying exclusively on their present state is required.
Alexander identified three basic requirements: objectivity, completeness and pluralism. The first requirement guarantees that the information is unbiased, the second assesses that the information should not be incomplete, the third stresses the importance of avoiding situations in which information is restricted to a particular viewpoint.
 Modeling Wikipedia
Modeling Wikipedia

I won't elaborate on their experiment in detail, but jump straight to the conclusion.
They claim to have proposed a transparent, noninvasive and automatic method to evaluate the
trustworthiness of Wikipedia articles. The method was able to estimate the trustworthiness of articles relying only on their present state, a characteristic needed in order to cope with the changing nature of Wikipedia.
 With a 1-in-ten-thousand chance of being destroyed each day, the article will rack up exactly seven million views over its lifetime.
With a 1-in-ten-thousand chance of being destroyed each day, the article will rack up exactly seven million views over its lifetime.

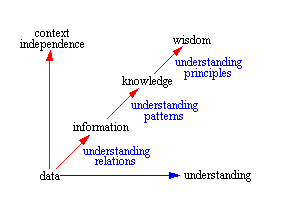 The idea is that information, knowledge, and wisdom are more than simply collections. Rather, the whole represents more than the sum of its parts and has a synergy of its own.
The idea is that information, knowledge, and wisdom are more than simply collections. Rather, the whole represents more than the sum of its parts and has a synergy of its own.



 The graph is plotted in logarithmic scale, and this data also fits well with exponential growth starting from October
The graph is plotted in logarithmic scale, and this data also fits well with exponential growth starting from October {kind=link}